• Regression is a field. There are sequences of classes taught about it. • Notation and terminology – Response variable yi is what we try to predict. – Predictor vector xi are attributes of the ith data point. – Coefficients β are regression parameters. • The two regression models everyone has heard of are – Linear regression for continuous responses, yi | xi ∼ N (β > xi ,σ 2 ) (6) – Logistic regression for binary responses (e.g., spam classification), p(yi = 1| xi) = logit(β > xi) (7) – In both cases, the distribution of the response is governed by the linear combination of coefficients (top level) and predictors (specific for the ith data point). • We can use regression for prediction. – The coefficient component βi tells us how the expected value of the response changes as a function of each attribute. – For example, how does the literacy rate change as a function of the dollars spent on library books? Or, as a function of the teacher/student ratio? – How does the probability of my liking a song change based on its tempo? • We can also use regression for description. 7 – Given a new song, what is the expected probability that I will like it? – Given a new school, what is the expected literacy rate? • Linear and logistic regression are examples of generalized linear models. – The response yi is drawn from an exponential family, p(yi | xi) = exp{η(β, xi) > t(yi)− a(η(β, xi))}. (8) – The natural parameter is a function η(β, xi) = f (β >xi). – In many cases, η(β, xi) = β >xi . • Discussion – In linear regression y is Gaussian; in logistic regression y is Bernoulli. – GLMs can accommodate discrete/continuous, univariate/multivariate responses. – GLMs can accommodate arbitrary attributes. – (Recall the discussion of sparsity and GLMs in COS513.) • Nelder and McCallaugh is an excellent reference about GLMs. (Nelder invented them.)
http://www.theanalysisfactor.com/confusing-statistical-term-4-hierarchical-regression-vs-hierarchical-model/
I find SPSS’s use of beta for standardised coefficients tremendously annoying!
BTW a beta with a hat on is sometimes used to denote the sample estimate of the population parameter. But mathematicians tend to use any greek letters they feel like using! The trick for maintaining sanity is always to introduce what symbols denote.
December 21, 2009 at 5:38 pm
Binomial regression
From Wikipedia, the free encyclopediaIn statistics, binomial regression is a technique in which the response (often referred to as Y) is the result of a series of Bernoulli trials, or a series of one of two possible disjoint outcomes (traditionally denoted "success" or 1, and "failure" or 0).[1] In binomial regression, the probability of a success is related to explanatory variables: the corresponding concept in ordinary regression is to relate the mean value of the unobserved response to explanatory variables.Binomial regression models are essentially the same as binary choice models, one type of discrete choice model. The primary difference is in the theoretical motivation: Discrete choice models are motivated using utility theory so as to handle various types of correlated and uncorrelated choices, while binomial regression models are generally described in terms of the generalized linear model, an attempt to generalize various types of linear regression models. As a result, discrete choice models are usually described primarily with a latent variable indicating the "utility" of making a choice, and with randomness introduced through an error variable distributed according to a specific probability distribution. Note that the latent variable itself is not observed, only the actual choice, which is assumed to have been made if the net utility was greater than 0. Binary regression models, however, dispense with both the latent and error variable and assume that the choice itself is a random variable, with a link function that transforms the expected value of the choice variable into a value that is then predicted by the linear predictor. It can be shown that the two are equivalent, at least in the case of binary choice models: the link function corresponds to the quantile function of the distribution of the error variable, and the inverse link function to the cumulative distribution function (CDF) of the error variable. The latent variable has an equivalent if one imagines generating a uniformly distributed number between 0 and 1, subtracting from it the mean (in the form of the linear predictor transformed by the inverse link function), and inverting the sign. One then has a number whose probability of being greater than 0 is the same as the probability of success in the choice variable, and can be thought of as a latent variable indicating whether a 0 or 1 was chosen.In machine learning, binomial regression is considered a special case of probabilistic classification, and thus a generalization of binary classification.Contents
[hide]Example application[edit]
In one published example of an application of binomial regression,[2] the details were as follows. The observed outcome variable was whether or not a fault occurred in an industrial process. There were two explanatory variables: the first was a simple two-case factor representing whether or not a modified version of the process was used and the second was an ordinary quantitative variable measuring the purity of the material being supplied for the process.Specification of model[edit]
The results are assumed to be binomially distributed.[1] They are often fitted as a generalised linear model where the predicted values μ are the probabilities that any individual event will result in a success. The likelihood of the predictions is then given bywhere 1A is the indicator function which takes on the value one when the event A occurs, and zero otherwise: in this formulation, for any given observation yi, only one of the two terms inside the product contributes, according to whether yi=0 or 1. The likelihood function is more fully specified by defining the formal parametersμi as parameterised functions of the explanatory variables: this defines the likelihood in terms of a much reduced number of parameters. Fitting of the model is usually achieved by employing the method of maximum likelihood to determine these parameters. In practice, the use of a formulation as a generalised linear model allows advantage to be taken of certain algorithmic ideas which are applicable across the whole class of more general models but which do not apply to all maximum likelihood problems.Models used in binomial regression can often be extended to multinomial data.There are many methods of generating the values of μ in systematic ways that allow for interpretation of the model; they are discussed below.Link functions[edit]
There is a requirement that the modelling linking the probabilities μ to the explanatory variables should be of a form which only produces values in the range 0 to 1. Many models can be fitted into the formHere η is an intermediate variable representing a linear combination, containing the regression parameters, of the explanatory variables. The function g is thecumulative distribution function (cdf) of some probability distribution. Usually this probability distribution has a range from minus infinity to plus infinity so that any finite value of η is transformed by the function g to a value inside the range 0 to 1.In the case of logistic regression, the link function is the log of the odds ratio or logistic function. In the case of probit, the link is the cdf of the normal distribution. The linear probability model is not a proper binomial regression specification because predictions need not be in the range of zero to one; it is sometimes used for this type of data when the probability space is where interpretation occurs or when the analyst lacks sufficient sophistication to fit or calculate approximate linearizations of probabilities for interpretation.Comparison between binomial regression and binary choice models[edit]
A binary choice model assumes a latent variable Un, the utility (or net benefit) that person n obtains from taking an action (as opposed to not taking the action). The utility the person obtains from taking the action depends on the characteristics of the person, some of which are observed by the researcher and some are not:where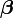 is a set of regression coefficients and
is a set of regression coefficients and  is a set of independent variables (also known as "features") describing person n, which may be either discrete "dummy variables" or regular continuous variables.
is a set of independent variables (also known as "features") describing person n, which may be either discrete "dummy variables" or regular continuous variables. 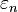 is a random variable specifying "noise" or "error" in the prediction, assumed to be distributed according to some distribution. Normally, if there is a mean or variance parameter in the distribution, it cannot be identified, so the parameters are set to convenient values — by convention usually mean 0, variance 1.The person takes the action, yn = 1, if Un > 0. The unobserved term, εn, is assumed to have a logistic distribution.The specification is written succinctly as:Let us write it slightly differently:Here we have made the substitution en = −εn. This changes a random variable into a slightly different one, defined over a negated domain. As it happens, the error distributions we usually consider (e.g. logistic distribution, standard normal distribution, standard Student's t-distribution, etc.) are symmetric about 0, and hence the distribution over en is identical to the distribution over εn.Denote the cumulative distribution function (CDF) of
is a random variable specifying "noise" or "error" in the prediction, assumed to be distributed according to some distribution. Normally, if there is a mean or variance parameter in the distribution, it cannot be identified, so the parameters are set to convenient values — by convention usually mean 0, variance 1.The person takes the action, yn = 1, if Un > 0. The unobserved term, εn, is assumed to have a logistic distribution.The specification is written succinctly as:Let us write it slightly differently:Here we have made the substitution en = −εn. This changes a random variable into a slightly different one, defined over a negated domain. As it happens, the error distributions we usually consider (e.g. logistic distribution, standard normal distribution, standard Student's t-distribution, etc.) are symmetric about 0, and hence the distribution over en is identical to the distribution over εn.Denote the cumulative distribution function (CDF) of as
as  and the quantile function (inverse CDF) of as
and the quantile function (inverse CDF) of as  Note thator equivalentlyNote that this is exactly equivalent to the binomial regression model expressed in the formalism of the generalized linear model.If
Note thator equivalentlyNote that this is exactly equivalent to the binomial regression model expressed in the formalism of the generalized linear model.If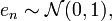 i.e. distributed as a standard normal distribution, thenwhich is exactly a probit model.If
i.e. distributed as a standard normal distribution, thenwhich is exactly a probit model.If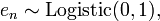 i.e. distributed as a standard logistic distribution with mean 0 and scale parameter 1, then the corresponding quantile function is the logit function, andwhich is exactly a logit model.Note that the two different formalisms — generalized linear models (GLM's) and discrete choice models — are equivalent in the case of simple binary choice models, but can be exteneded if differing ways:
i.e. distributed as a standard logistic distribution with mean 0 and scale parameter 1, then the corresponding quantile function is the logit function, andwhich is exactly a logit model.Note that the two different formalisms — generalized linear models (GLM's) and discrete choice models — are equivalent in the case of simple binary choice models, but can be exteneded if differing ways:- GLM's can easily handle arbitrarily distributed response variables (dependent variables), not just categorical variables or ordinal variables, which discrete choice models are limited to by their nature. GLM's are also not limited to link functions that are quantile functions of some distribution, unlike the use of an error variable, which must by assumption have a probability distribution.
- On the other hand, because discrete choice models are described as types of generative models, it is conceptually easier to extend them to complicated situations with multiple, possibly correlated, choices for each person, or other variations.
Latent variable interpretation / derivation[edit]
A latent variable model involving a binomial observed variable Y can be constructed such that Y is related to the latent variable Y* viaThe latent variable Y* is then related to a set of regression variables X by the modelThis results in a binomial regression model.The variance of ϵ can not be identified and when it is not of interest is often assumed to be equal to one. If ϵ is normally distributed, then a probit is the appropriate model and if ϵ is log-Weibull distributed, then a logit is appropriate. If ϵ is uniformly distributed, then a linear probability model is appropriate.
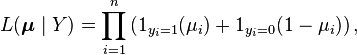


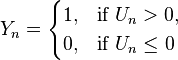
![\begin{align}
\Pr(Y_n=1) &= \Pr(U_n > 0) \\[6pt]
&= \Pr(\boldsymbol\beta \cdot \mathbf{s_n} - e_n > 0) \\[6pt]
&= \Pr(-e_n > -\boldsymbol\beta \cdot \mathbf{s_n}) \\[6pt]
&= \Pr(e_n \le \boldsymbol\beta \cdot \mathbf{s_n}) \\[6pt]
&= F_e(\boldsymbol\beta \cdot \mathbf{s_n})
\end{align}](https://upload.wikimedia.org/math/d/2/9/d29e4c4bbf77e634efb4eeb706c2f49c.png)
 is a
is a ![\mathbb{E}[Y_n] = \Pr(Y_n = 1),](https://upload.wikimedia.org/math/3/9/d/39d7e61091bc67ceadd3c7844a69f007.png) we have
we have![\mathbb{E}[Y_n] = F_e(\boldsymbol\beta \cdot \mathbf{s_n})](https://upload.wikimedia.org/math/f/9/2/f92668779055ee5f9ca9ae26d8cd6a38.png)
![F^{-1}_e(\mathbb{E}[Y_n]) = \boldsymbol\beta \cdot \mathbf{s_n} .](https://upload.wikimedia.org/math/6/a/9/6a959972d8bbcbbcd80fdf2450329240.png)
![\Phi^{-1}(\mathbb{E}[Y_n]) = \boldsymbol\beta \cdot \mathbf{s_n}](https://upload.wikimedia.org/math/6/9/0/690bb00742789aadcc60b97e27c8e7ba.png)
![\operatorname{logit}(\mathbb{E}[Y_n]) = \boldsymbol\beta \cdot \mathbf{s_n}](https://upload.wikimedia.org/math/e/d/f/edf06cca571d3bca07785408b4d7632a.png)
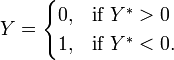

No comments:
Post a Comment