http://www.tandfonline.com/doi/pdf/10.1080/10473289.2000.10464039
NEURAL COMPUTING The Structure of the Brain The approach of neural computing is to apply to computer systems the guiding principles that underlie the brain’s solution to problems.9 We know that the brain is organized in layered structures and uses many slow units that are highly interconnected (parallel). The human brain contains approximately 10,000 million (1010) basic units called neurons that are highly interconnected—every neuron is connected to about 10,000 (104) others. The neuron accepts many inputs, which are all added up in some (i.e., nonlinear) fashion, and produces an output if this sum is greater than some value, known as the threshold value. The inputs to the neuron arrive via chemical connections called synapses. These junctions alter the effectiveness of the transmitted signal. If enough active inputs are received at once, then the neuron will be activated and produce an output; otherwise, it will remain in its inactive state. Learning occurs when the effective coupling between one cell and another is modified.
NEURAL COMPUTING The Structure of the Brain The approach of neural computing is to apply to computer systems the guiding principles that underlie the brain’s solution to problems.9 We know that the brain is organized in layered structures and uses many slow units that are highly interconnected (parallel). The human brain contains approximately 10,000 million (1010) basic units called neurons that are highly interconnected—every neuron is connected to about 10,000 (104) others. The neuron accepts many inputs, which are all added up in some (i.e., nonlinear) fashion, and produces an output if this sum is greater than some value, known as the threshold value. The inputs to the neuron arrive via chemical connections called synapses. These junctions alter the effectiveness of the transmitted signal. If enough active inputs are received at once, then the neuron will be activated and produce an output; otherwise, it will remain in its inactive state. Learning occurs when the effective coupling between one cell and another is modified. Modeling the Brain The model neuron (Figure 1) must capture the biological neuron’s important features; perform a weighted sum of its inputs xi , compare this to some internal threshold level, and turn on only if this level is exceeded. If we call the output y, we can write y = f [∑wijxi ] where f is a monotonic increasing function called the thresholding function. In turn, this response serves as an input signal to other neurons. Artificial NN models can be constructed by suggesting different ways of connecting processing elements organized in one or more layers. The simpler feedforward network has two layers in which a set of input patterns arriving at an input layer (involving input units) are mapped directly to a set of output patterns at an output layer (involving output units). Such networks can only map similar input patterns to similar output patterns. Whenever the similarity structure of the input and output patterns are very different, only a network with internal representation (hidden units) can perform the necessary mappings.10 NNs of this form (multilayer feedforward) are illustrated in Figure 2 and can realize any arbitrarily complicated and non-linear functional relationship between its inputs and its outputs.11 The NNs employed here are trained by supervised learning, which is achieved in two stages. In the training
stage, the network is provided with a training data set (input plus desired output) and by implementing specific iterative algorithms, which adjust the coupling (synaptic weights) between neurons, the network is able to reproduce these examples. When the training stage has been completed, the values of the synaptic weights are fixed and a test set of unknown records is presented to the NN (testing stage). The Backpropagation Algorithm Suppose we have a multilayered feedforward NN with one input layer, N hidden layers, and one layer of output units. We use the following notation: Aip (m) = unit’s actual output; Tip = unit’s target output; Wij (m) = synaptic weights; and δjp (m) = learning parameter; where the superscript (m) denotes a layer within the structure of the NN (m = 0 for the input layer, m = 1,2,...,N for the hidden layers, m = N + 1 for the output layer), subscripts i and j label a unit within a layer, and subscript p labels the input patterns. Finally, thresholds are considered as weights emanating from units of constant output equal to one. The equation describing the node output can then be written as
http://www.tandfonline.com/doi/pdf/10.1080/10473289.2000.10464039
神经计算脑的神经计算的方法是适用于计算机系统背后大脑的解决方案,以problems.9我们知道,大脑中的分层结构组织并使用高度互连的慢很多单位(指导原则的结构平行)。人类的大脑包含大约10,000万元(1010)称那是高度神经元基本单元相互连接,每个神经元连接到约10,000(104)等。神经元接受许多输入,它们都在一些(即,非线性)时尚相加,并且如果这个总和大于某个值,被称为阈值时产生一个输出。对神经元的输入通过一个叫做突触的化学连接到达。这些结改变所发射的信号的有效性。如果在一旦收到足够活性的输入,则神经元将被激活,并产生一个输出;否则,它会留在无效状态。当一个细胞和另一种之间的有效耦合被修改时学习。
神经计算脑的神经计算的方法是适用于计算机系统背后大脑的解决方案,以problems.9我们知道,大脑中的分层结构组织并使用高度互连的慢很多单位(指导原则的结构平行)。人类的大脑包含大约10,000万元(1010)称那是高度神经元基本单元相互连接,每个神经元连接到约10,000(104)等。神经元接受许多输入,它们都在一些(即,非线性)时尚相加,并且如果这个总和大于某个值,被称为阈值时产生一个输出。对神经元的输入通过一个叫做突触的化学连接到达。这些结改变所发射的信号的有效性。如果在一旦收到足够活性的输入,则神经元将被激活,并产生一个输出;否则,它会留在无效状态。当一个细胞和另一种之间的有效耦合被修改时学习。模拟大脑中的神经元模型(图1)必须捕获生物神经元的重要特征;执行其输入Xi的加权和,比较这对一些内部阈值水平,并开启仅如果超过这一水平。如果我们调用输出y,我们可以写Y = F [Σwijxi]其中f是被称为阈值函数的单调递增函数。反过来,这响应作为输入信号到其他神经元。人工神经网络模型可以推荐连接在一个或多个层组织处理元件的不同的方式来构造。简单的前馈网络具有其中一组在输入层到达(涉及输入单元)输入图案在输出层直接映射到一组输出模式(涉及输出单元)两个层。这种网络只能映射相似的输入模式,以相似的输出模式。每当输入和输出模式的相似性结构有很大的不同,只有内部表示(隐藏单元)的网络可以执行这种形式的(多层前)的必要mappings.10神经网络在图2中示出,并且可以实现任何任意复杂和其输入,其outputs.11这里所用的神经网络之间的非线性函数关系由监督学习,这是在两个阶段中实现的训练。在训练
阶段,网络设置有一训练数据集(输入加上所需的输出),并通过实施特定的迭代算法,调节神经元之间的耦合(突触加权值),该网络能够再现这些实施例。当训练阶段已经完成,突触权重的值是固定的,并设置的未知记录测试呈现给NN(测试阶段)。反向传播算法假设我们有一个多层前馈神经网络具有一个输入层,N隐层和输出单元一层。我们用下面的符号:AIP(M)=单位的实际输出;提示=单位的目标输出; WIJ(M)=突触权重;和δjp(米)=学习参数;其中,上标(m)表示对NN的结构内的层(m = 0时的输入层,M = 1,2,...,N为隐藏层,M = N + 1的输出层) ,下标i和j标签的层内的单元,并且下标p标记的输入模式。最后,阈值被认为是从等于一个恒定的输出为单位发出的权重。描述节点输出方程然后可以写为
人工智能中的联结主义和符号主义
2016年03月16日 15:39 来源于 财新网
虽然人工智能取得了突破性进展,但是他还是在婴幼儿时期。联结主义的方法虽然摧枯拉朽,无坚不摧,但是依然没有坚实的理论基础
文|顾险峰(纽约州立大学石溪分校计算机系终身教授)
最近,谷歌AlphaGo败了围棋九段李世石,举世震惊。有为人工智能的发展欢呼雀跃者,有为人类前途命运忧心忡忡者,有对机器蛮力不屑一顾者,有对人类失去优越感而沮丧彷徨者。这里,探讨人工智能发展的主要方向,目前的局限和未来的潜力,特别是将人类脑神经认知和人工神经网络认知进行对比,从而对人工智能有一个公正客观,而又与时俱进的认识。
人类的智能主要包括归纳总结和逻辑演绎,对应着人工智能中的联结主义(如人工神经网络)和符号主义(如吴文俊方法)。人类大量的视觉听觉信号的感知处理都是下意识的,基于大脑皮层神经网络的学习方法;大量的数学推导,定理证明是有强烈主观意识的,是基于公理系统的符号演算方法。
1联结主义
DavidHunter Hubel和Torsen Wiesel共同获得了1981年诺贝尔生理学或医学奖。1959年,Hubel和Wiesel在麻醉的猫的视觉中枢上插入微电极,然后在猫的眼前投影各种简单模式,观察猫的视觉神经元的反映。他们发现,猫的视觉中枢中有些神经元对于某种方向的直线敏感,另外一些神经元对于另外一种方向的直线敏感;某些初等的神经元对于简单模式敏感,另外一些高级的神经元对于复杂模式敏感,并且其敏感度和复杂模式的位置与定向无关。这证明了视觉中枢系统具有由简单模式构成复杂模式的功能。这也启发了计算机科学家发明了人工神经网络。
层次特征(Hierarchical Features )
后来,通过对猴子的视觉中枢的解剖,将猴子的大脑皮层曲面平展在手术台表面上,人们发现从视网膜到第一级视觉中枢的大脑皮层曲面的映射(Retinotopicmapping)是保角映射 (Conformal Mapping)[1]。如图1所示,保角变换的最大特点是局部保持形状,但是忽略面积大小。这说明视觉处理对于局部形状非常敏感。
 |
人们逐步发现,人类具有多个视觉中枢,并且这些视觉中枢是阶梯级联,具有层次结构。人类的视觉计算是一个非常复杂的过程。如图2所示,在大脑皮层上有多个视觉功能区域(v1至v5等),低级区域的输出成为高级区域的输入。低级区域识别图像中像素级别的局部的特征,例如边缘折角结构,高级区域将低级特征组合成全局特征,形成复杂的模式,模式的抽象程度逐渐提高,直至语义级别。
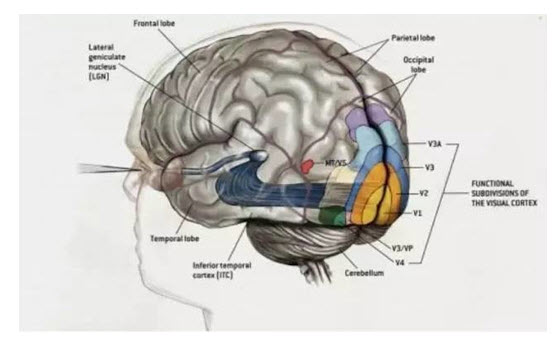 |
图2 大脑皮层的视觉中枢,视觉信号的传导途径:视网膜,LGN, V1, V2, V3, V4, V5 等
|
如图3所示,毕加索的名画格尔尼卡(Guernica)中充满了抽象的牛头马面,痛苦嚎哭的人脸,扭曲破碎的肢体。我们可以毫不费力地辨认出这些夸张的几 何形体。其实,图中大量信息丢失,但是提供了足够的整体模式。由此可见,视觉高级中枢忽略色彩、纹理、光照等局部细节,侧重整体模式匹配和上下文关系,并可以主动补充大量缺失信息。
 |
最近,深度学习技术的发展,使得人们能够模拟视觉中枢的层级结构,考察每一级神经网络形成的概念。图4显示了一个用于人脸识别的人工神经网络经过训练后习得的各层特征。底层网络总结出各种边缘结构,中层网络归纳出眼睛,鼻子,嘴巴等局部特征,高层网络将局部特征组合,得到各种人脸特征。这样,人工神经网络佐证了视觉中枢的层次特征结构。
 |
专用和通用(Specific vs. General )
人工神经网络在20世纪80年代末和90年代初达到巅峰,随后迅速衰落,其中一个重要原因是因为深度神经网络的发展严重受挫。人们发现,如果网络的层数加深,那么最终网络的输出结果对于初始几层的参数影响微乎其微,整个网络的训练过程无法保证收敛。
同时,人们发现大脑具有不同的功能区域,每个区域专门负责同一类的任务,例如视觉图像识别, 语音信号处理和文字处理等等。并且在不同的个体上,这些功能中枢在大脑皮层上的位置大致相同。在这一阶段,计算机科学家为不同的任务发展出不同的算法。例如,为了语音识别,人们发展了隐马尔科夫链模型;为了人脸识别,发展了Gaber滤波器,SIFT滤波,马尔科夫随机场的图模型。因此,在这个阶段,人们倾向于发展专用算法。
脑神经科学的几个突破性进展使人们彻底改变了看法。2000年左右,Jitendra Sharma在《自然》上撰文[2],汇报了他们的一个令人耳目一新的实验。Sharma把幼年鼬鼠的视觉神经和听觉神经剪断,交换后接合,眼睛接到了听觉中枢,耳朵接到了视觉中枢。鼬鼠长大后,依然发展出了视觉和听觉。这意味着大脑中视觉和听觉的计算方法是通用的。
2009年,Vuillerme和 Cuisinier为盲人发明了一套装置[3],将摄像机的输出表示成二维微电极矩阵,放在舌头表面。盲人经过一段时间的学习训练,可以用舌头“看到”障碍物。在2011年,人们发现许多盲人独自发展出一套“声纳”技术,他们可以通过回声来探测并规避大的障碍物。Thaler等研究表明,他们“声纳”技术采用的并不是听觉中枢,而是原来被废置的视觉中枢。
种种研究表明,大脑实际上是一台“万用学习机器”(Universallearning Machine),同样的学习机制可以用于完全不同的的应用(图5)。人类的DNA并不提供各种用途的算法,而只提供基本的普适的学习机制,人的思维功能主要是依赖于学习所得。后天的文化和环境决定了一个人的思想和能力。换句话而言,学习的机制人人相同,但是学习的内容决定了人的mind。
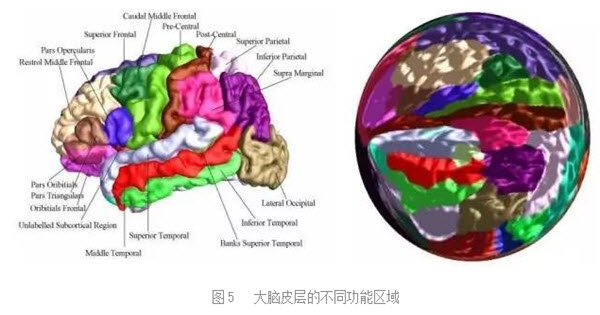 |
可塑性(Plasticity)
人的大脑具有极强的可塑性,许多功能取决于后天的训练。例如,不同民族语言具有不同的元音和辅音,阿拉伯语最为复杂,日语相对简单。出生不久的婴儿可以辨别听出人类能够发出的所有元音和辅音。但是在五岁左右,日本幼儿已经听不出很多阿拉伯语中的音素了。同样,欧洲人可以非常容易地辨认本民族面孔,但是非常容易混淆亚洲人面孔。人们发现,如果大脑某个半球的一个区域受损,产生功能障碍。依随时间流逝,另一半球的对称区域会“接替”受损区域,掌管相应功能。这些都表明大脑神经网具有强烈的可塑性。
长期以来,人们倾向于认为大脑神经元网络依随学习和训练,其联结复杂度逐渐增加,愈来愈多的联结建立起来。近期,一些神经科学家提出了相反的看法。他们观察到,婴儿睡觉时,如果有剪刀掉到地上,婴儿的应激反应是全身的,而相对成熟的儿童的应激反应只集中在局部肌肉上面。他们找到一些证据表明,婴儿的某些神经网络是全联通图,依随年龄的增长和学习训练的积累,许多神经联结会自行断开,从而形成简化的网络。
梦的解析(Dream)
大脑学习算法的普适性和可塑性一直激励着计算机科学家不懈地努力探索。历史性的突破发生在2006年左右。三位计算机科学家,Geoffrey Hinton,Yann LeCun 和 Yoshua Bengio突破了深度学习的技术瓶颈,引领了深度学习的浪潮。相比于以前的状况,主要的技术突破在于以下几点:优化方法的改进,更加简单的优化方法,特别是随机梯度下降方法的应用;使用非监督数据来训练模型以达到特征自动提取;使用越来越大的数据集;深度神经网络和大数据训练需要巨大的计算能力,GPU 的普遍使用解决了这一迫切要求;等。现在,深度学习方法突飞猛进,在图像识别(Image Registration),文本处理(text),语音处理(speech)等领域的基本问题上,都已经超过了传统方法。在图像识别领域,2015年深度学习方法的识别准确率已经达到人类的水平[4]。
同时,对于深度学习神经网络的理解加深了人 类对于自身智力活动的理解。长期以来,人们对于梦境一直没有很好的理解。一直解释观点如下,如图7所示,大脑中有一对海马体(Hipocampus,,图6),它们和人类的长期记忆有关。如果把大脑比喻成一个数据库,那么海马体就像是索引。如果海马体有问题,那么许多存入的记忆无法被取出,同时也无法形成新的记忆。每天晚上,海马体将当天形成短暂记忆加工成长期记忆,在这一过程中,就形成了梦。海马体和其他神经中枢相连,处理其它中枢已经处理好的数据,形成新的编码。海马体和视觉和听觉中枢直接相连,因此,在梦中能够看到并且听到;但是,海马体和嗅觉中枢并不相连,因此,在梦中无法闻到气味。我们在梦中经常能够看到平时看不到的奇诡景象,可以用深度学习的方法加以模拟解释。
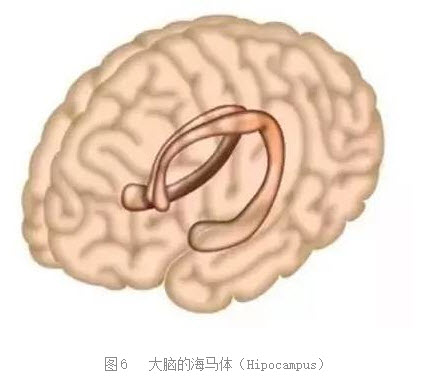 |
实际上,视觉处理的过程并不只是从低级向高级传递的单向过程,高级中枢可以向低级中枢发出反馈信息,最为明显的例子是高级中枢可以决定低级中枢的“注意力”和“焦点”。当看到模糊不清的图像,或者一时无法辨认的图像时,高级中枢会产生各种概率上合理的解释,并且由这种猜测先入为主地 影响低层中枢的判断,从而产生错觉。如图7所示,可以用深度学习的神经网络来模拟这种先入为主的现象。输入是一幅白噪声,本身没有任何有意义的信息。网络由于随机涨落,在某一刹那倾向认为图中有香蕉。由此,优化这幅图像,使得识别香蕉的高层神经元兴奋,如此得到的图像果真看起来像香蕉。
 |
图8显示了一个例子,这里输入的是一幅羚羊图像。神经网络的低级反馈加到图像上,看到许多边缘和定向的模式出现在场景里。
 |
许多孩子喜欢仰望蓝天白云,并且用自己丰富的想象力看到了各种奇妙的幻象。如图9所示,将一幅蓝天白云的图像作为输入,用一个识别动物的深度学习神经网络加以处理,将高层神经元的认知模式作为反馈,来优化原始图像,结果可以看到各种山海经中才会出现的神兽:身着铠甲的将军狗,猪蜗牛,骆驼鸟,狗鱼。人在做梦时,高层神经元对于低层神经元发出各种反馈,低层神经元将图像依照高层的意图进行诠释幻化,视觉幻象由此产生。
 |
 |
美学(Aesthetics)
很久以来,人们倾向于认为机器可以理解人类的逻辑思维,但却无法理解人类的丰富感情,更无法理解人类的美学价值,当然机器也就无法产生具有美学价值的作品。事实胜于雄辩,AlphaGo对局李世石下出石破天惊的一步,棋圣聂卫平先生向AlphaGo的下法脱帽致敬,这说明深度学习算法已经能够自发创造美学价值。许多棋手在棋盘方寸间纵横一生,所追寻的就是美轮美奂的神机妙手。如此深邃优美,玄奥抽象,一夜间变成了枯燥平淡的神经元参数,这令许多人心生幻灭。
其实,在视觉艺术领域,人工神经网络已经可以将一幅作品的内容和风格分开,同时向艺术大师学习艺术风格,并把艺术风格转移到另外的作品中,用不同艺术家的风格来渲染同样的内容[6],如图10所示。
 |
 |
这意味着人工神经网络可以精确量化原本许多人文科学中模糊含混的概念,例如特定领域中的”“艺术风格”,博弈中的“棋风”,并且使这些只可意会,无法言传的技巧风格变得朴实无华,容易复制和推广。
2符号主义
人工智能中,符号主义的一个代表就是机器定理证明,其巅峰之作是吴文俊先生创立的吴文俊方法。目前机器定理证明的理论根基是希尔伯特定理:多元多项式环中的理想都是有限生成的。我们首先将一个几何命题的条件转换成代数多项式,同时把结论也转换成多项式,然后证明条件多项式生成的理想包含结论对应的多项式,即将定理证明转换为理想成员判定问题。一般而言,多项式理想的基底并不唯一,Grobner基方法和吴方法可以生成满足特定条件的理想基底,因此都可以自动判定理想成员问题。因此理论上代数范畴的机器定理证明可以被完成。但是,实际中这种方法有重重困难。
首先,从哲学层面上讲,希尔伯特希望用公理化方法彻底严密化数学基础。哥德尔证明了对于任何一个包含算术系统的公理体系,都存在一个命题,其真伪无法在此公理体系中判定。换言之,这一命题的成立与否都与此公理体系相容。这意味着我们无法建立包罗万象的公理体系,无论如何,总存在真理游离在有限公理体系之外;另一方面,这也意味着对于真理的探索过程永无止境。
其次,从计算角度而言,Grobner基方法和吴方法的复杂度都是超指数级别的,即便对于简单的几何命题,其机器证明过程都可能引发存储空间的指数爆炸,这揭示了机器证明的本质难度。
第三,能够用理想生成的框架证明的数学命题,其本身应该是已经被代数化了。例如所有的欧几里得几何命题,初等的解析几何命题。微分几何中的许多问题的代数化,本身就是非常具有挑战性。例如黎曼流形的陈省身-高斯-博内定理:流形的总曲率是拓扑不变量。如果没有嘉当发明的外微分和活动标架法,这一定理的证明无法被代数化。拓扑学中的许多命题的代数化本身也是非常困难的,比如众所周知的布劳威尔不动点定理:我们用咖啡勺缓慢均匀搅拌咖啡,然后抽离咖啡勺,待咖啡静止后,必有一个分子,其搅拌前和搅拌后的位置重合。这一命题的严格代数化是一个非常困难的问题。吴先生的高徒,高小山研究员突破的微分结式理论,系统地将这种机器证明方法从代数范畴推广到微分范畴[7]。
最后,机器定理证明过程中推导出的大量符号公式,人类无法理解其内在的几何含义,无法建立几何直觉。而几何直觉和审美,实际上是指导数学家在几何天地中开疆拓土的最主要的原则。机器无法抽象出几何直觉,也无法建立审美观念,因此虽然机器定理证明经常对于已知的定理给出令人匪夷所思的新颖证明方法,但是迄今为止,机器并没有自行发现深刻的未知数学定理。
比如,人类借助计算机完成了地图四色定理的证明,但是对于这一证明的意义一直富有争议。首先,是人类将所有可能情形进行分类,由机器验证各类情形;其次,这种暴力证明方法没有提出新的概念,新的方法;再次,这个证明没有将这个问题和其它数学分支发生深刻内在的联系。数学中,命题猜测的证明本身并不重要,真正重要的是证明所引发的概念思想,内在联系和理论体系。因此,许多人认为地图四色定理的证明实际上“验证”了一个事实,而非“证明”了一个定理。
因此,和人类智慧相比,人工智能的符号主义方法依然处于相对幼稚的阶段。
3展望
虽然人工智能取得了突破性进展,但是他还是在婴幼儿时期。联结主义的方法虽然摧枯拉朽,无坚不摧,但是依然没有坚实的理论基础。通过仿生学和经验积累得到的突破,依然无法透彻理解和预测。简单的神经网络学习机制加上机器蛮力,能否真正从量变到质变,这需要时间检验。
围棋是信息完全博弈游戏的巅峰,但不是人类智力的巅峰。理性思维的巅峰还是数学物理理论的创立。许多抽象的数学定理,本身的描述已经概念嵌套概念,并且在现实物理世界中找不到示例,因此机器学习方法不再适用。比如下面的命题:高斯曲率处处为负的封闭曲面无法嵌入在三维欧式空间中。这一命题的证明无法用目前符号计算的方法,也无法用机器学习的方法。如果有朝一日,数学家开始对人工智能脱帽致敬,那么人类应该开始警醒了。
人类的孩子需要花费十数年来学习,并且学习中师生和同学中的社会交往起到了至关重要的作用。目前人工智能的程序还是各自训练,彼此之间没有交互。如果人工智能程序间能够建立社会交往,彼此交换学习内容和心得,那么人工智能将会产生新的飞跃。比如一群谷歌的Atlas机器人,装备了AlphaGo的大脑,彼此自发地进行篮球游戏。通过拷贝神经网络的参数,它们可以彼此迅速交换学习成果。通过对抗演练,它们能够迅速提高手眼协调,团队协作,则很快有望进入NBA。
谷歌旗下的机器人
 |
我们可以相信,不久的将来,人类和人工智能机器人和睦共处,共同学习提高。在纽约曼哈顿中央公园,有机器人在辛勤地劳作,也有人类遛着阿尔法狗。街角,有个 Atlas在和人类攀谈,切磋着各种幽默笑话。不远处的长椅上另一个Atlas默默地坐着,它头戴虚拟现实的眼镜,在孜孜不倦地学习着人类历史……■
参考文献(References)
[1]Brewer,Alyssa A. et. al. "Visual field maps and stimulus selectivity in humanventral occipital cortex." Nature neuroscience 8.8 (2005): 1102-1109.
[2]JitendraSharma, Alessandra Angelucci and Mriganka Sur, Induction of visual orientationmodules in auditory cortex, Nature 404, 841-847 (20 April 2000)
[3]NicolasVuillerme and Remy Cuisinier, Sensory Supplementation through TongueElectrotactile Stimulation to Preserve Head Stabilization in Space in theAbsence of Vision, Visual Psychophysics and Physiological Optics , January 2009
[4]Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, DeepResidual Learning for Image Recognition, CVPR2016.
[5]http://googleresearch.blogspot.com/2015/06/inceptionism-going-deeper-into-neural.html
[6]https://github.com/jcjohnson/neural-style
[7]X.S.Gao, W.Li, C.M. Yuan, Intersection Theory in DifferentialAlgebric Geometry: Generic Intersections and the Differential Chow Form, Trans.Amer. Math. Soc., 365(9), 4575-4632, 2013.
 |
| 知识分子 |
《知识分子》是由饶毅、鲁白、谢宇三位学者创办的移动新媒体平台,致力于关注科学、人文、思想
No comments:
Post a Comment