http://mathworld.wolfram.com/BivariateNormalDistribution.html
http://blogs.sas.com/content/iml/2013/09/18/compute-a-contour-level-curve-in-sas.html
http://support.sas.com/documentation/cdl/en/imlug/59656/HTML/default/viewer.htm#nonlinearoptexpls_sect15.htm
Example 14.1 Chemical Equilibrium :: SAS/IML(R) 12.3 ...
support.sas.com/documentation/cdl/en/.../viewer.htm#...
number of moles for compound $j$ , $j=1,\ldots ,n$. $s$. total number of moles in the mixture, $s=\sum _{i=1}^ n x_ j$. $a_{ij}$. number of atoms of element $i$ ...
SAS Institute
The problem is to determine the parameters 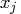 that minimize the objective function
that minimize the objective function 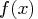 subject to the nonnegativity and linear balance constraints.
subject to the nonnegativity and linear balance constraints.
 |
Moles of CompoundsThe concept of a mole can be applied to compounds as well as elements. A mole of a compound is what you have when you weigh out, in grams, the formula weight of that compound. (Use the molecular weight if the compound is a molecular material.) For example, the formula weight for HF is 20.0. That means that one mole of HF weighs 20.0 grams, and you can use that relationship to convert back and forth between grams and moles.
Clackamas Community College ©1998, 2002 Clackamas Community College, Hal Bender What is the difference between linear and non-linear optimization?
What are the algorithms used for the different class of problems?
2 Answers
In linear optimization, the boundary of feasible range is hyperplane and cost function is linear, too. If any of the constraints or the obj function is non-linear, the problem becomes non-linear optimization.
In optimization, there is a big difference between convex optimization and non-convex optimization, however, there is no intrinsic difference between linear programming and nonlinear programming. Linear programming was studied first because it is easier to think in the pre-computer age. Simplex was popular mainly because it is easy to write down in paper (it is a tabular-based method). Note that complexity of Simplex is exponential. Most of the polynomial-time algorithms (like interior point methods) work for both linear and non-linear programming.
I am no expert, but here's some info:
In linear optimization the cost function is a hyperplane with some slope. Some features have a positive weight, and if you increase those you will always increase the objective function. On the other hand, some features have negative weight and will always reduce it. So it's quite easy to optimize. The interesting part is when you throw in constraints. If you have linear inequality constraints then you can move around the border trying to find a way downhill again, which is what the most prominent algorithm, the simplex algorithm, tries to do. Linear problems are very typical of planning problems and Operations Research and often involve an enormous number of features, leading to programs such as CPLEX branding themselves on being able to solve equations with billions of variables. Non-linear optimization deals with, you guessed it, non-linear functions. Usually you distinguish between convex and non-convex optimization with the former being less ill-specified than the latter as it is unimodal. Typical methods of solving these problems are first-order methods such as gradient and conjugate gradient descent, and second order methods (and approximations thereof) such as Newton's method and Levenberg-Marquardt. One of the most prominent algorithms is the BFGS algorithm. There are a ton of variations on the above, but these are amongst the typical topics covered in an optimization textbook, in my experience. Check out Nocedal and Wright's "Numerical Optimization" for a good if technical textbook. |


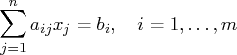
![f(x) = \sum_{j=1}^n x_j [c_j + \ln ( {x_j \over s} ) ]](http://support.sas.com/documentation/cdl/en/imlug/59656/HTML/default/images/nonlinearoptexpls_nonlinearoptexplseq238.gif)
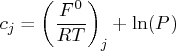
No comments:
Post a Comment